A phantom has been haunting me: a deep dive into SMBGhost (part 1)
What is SMBGhost
SMBGhost (CVE-2020-0796) is a vulnerability affecting SMB 3.1, and more precisely one of its decompression function.
As SMB 3.1 added support for data compression in order to save bandwidth, it added a decompression function presenting an integer overflow resulting in multiple subsequent buffer overflows. Those buffer overflows are exploitable in a way that allows an attacker to achieve unauthenticated remote code execution.
SMBGhost is a perfect case study for hackers eager to familiarize themselves with somewhat recent exploit mitigation circumvention in modern Windows’ kernel. SMBGhost was critical enough that it was heavily studied, is old enough that it is already documented a lot ; while being recent enough that the principles used are still relevent.
The aim in this serie of articles will be to explain the vulnerability in itself, but more importantly, to become more familiar with:
The tools and process used to idenitfy where the vulnerability was is Windows’ code
How Windows manage memory
The primitives used through the exploit. i.e, how do you turn arbitrary read of physical addresses into arbitrary read of virtual addressess?
How to circumvent ASLR and other modern defenses against exploitation
How do you turn an arbitrary write and ASLR bypass into actual code execution ?
So buckle up, as there is a lot to cover. I’ll try to explain it in a way that you don’t need to be a kernel dev expert to understand, as I sure as hell am not, and all the concepts seen here were mostly new to me anyway.
Also, nothing here is new, I’m just going to go over every steps that previous researchers already did, while explaining them with my own words.
SMB compression in SMB 3.1
Before delving into the vulnerability, let’s see how compression/decompression is supposed to work in SMB, as this was a subject that 1°) I felt was not really touched on too much by researchers, 2°) will make it smoother to understand the vulnerability.
So how does it happen ? On a really broad level, the SMB client sends a special SMB packet that contains data. This data is compressed, BUT, what was not really clear to me from the beginning, is that the packet can contain a mix of both uncompressed / normal and compressed data.
The SMB client also sends a few variables, inside the packet meta data, so that the server is able to decompress the compressed data, most notably:
The offset to the compressed data
The size of the compressed data, but before it got compressed
The compression algorithm used
Still at a broad level, here’s what an example of conversation between a SMB client and SMB server would look like:
Example conversation between smb client and server with compression
If we start getting into the details, the packet used to send the message is described by Microsoft here.
Structure of a SMB packet used to transfer compressed data
What matters most to us is the Offset field and the OriginalCompressedSegmentSize.
The Offset is used to notify the server where the compressed data start in the SMB packet. In our previous examples, Offset was 40 bytes, meaning that 40 bytes after the SMB packet would lay the compressed data.
The OriginalCompressedSegmentSize is the size of the compressed data before compression. When sending compressed data, the client also sends what size it originally was.
Do you start to see where the problem might arise ? The Offset and OriginalCompressedSegmentSize are both size of something. They’re under the control of the client. So, what happens if the client states an Offset or OriginalCompressedSegmentSize that is not representative of reality?
If developers predicted that kind of unindented behavior, nothing serious should happen. If however, they did not, one might expect some kind of memory corruption bug to take place, buffer overflows being the main suspect.
Of course this is all rethoric, as I would not be writing about it otherwise. Now, let’s check how the server actually handles those edge cases.
How the SMB server decompresses a compressed packet: reversing srv2.sys
The first question is obviously: where are those SMB functions implemented in Windows? This is where I was a bit lazy and just went with what the already existing articles on SMBGhost stated: the vulnerability lies in the driver srv2.sys, more precisely in the function Srv2DecompressData. A more general approach would have been to diff the patch by Microsoft and pinpoint what files/functions changed. However, as this blog will be long enough, I won’t go in details on how to do that.
While I created a whole Virtual Machine just to get the srv2.sys driver, I since then learned about this website, on which you can download pretty much any version of any Windows binary. Those who wishes to follow can download a vulnerable version of srv2.sys directly from it.
Reversing Srv2DecompressData with either Ghidra or IDA Pro will give you the usual abstruse lines of code that you get from reversing basically anything.
Your main goal when reversing something is to grasp anything, which will help you to understand a little bit more about the surrounding code, which in turn will help you understand a little bit more, etc. From my experience, those little bit of knowledge come from 3 things:
By recognizing known structures. For example, if you know a structure from some documentation, and you find a pointer that 1°) is accessed through the same offsets of the structure 2°) the fields at those offset is coherent with the structure ; then it is obvious that the pointer points to an instance of the structure from the documentation. Dynamic analysis is extremely helpful here.
From the PDB files. For example, we already have some function names in the code above, which comes from the symbols that Microsoft let us access
And of course, from googling if any reverse engineering has already been done on the driver, or another part of the kernel with which it shares structures
In our case of course, a lot of reverse engineering has already been done, as the vulnerability has been studied in details by multiple independant researchers. But we’ll try to redo that work from the information those researchers had at the time, which I think will be a more fruitfull learning experience.
From the data we already have, we can see that the function called “SrvNetAllocateBuffer” is called, and its output is saved and used later.
As the name suggest, SrvNetAllocateBuffer is probably used to allocate a buffer. Why would we need to allocate a buffer in a function supposed to decompress a packet? Well, to store the data once decompressed seems like a good answer.
Futhermore, we can see that the first argument to SrvNetAllocateBuffer is the sum of two unsigned int.
As we said earlier, when using compression with SMB, we send compressed data, BUT we can also send “normal” (not compressed) data in the same packet. Knowing this, it becomes apparent that the size of the final data is the sum of two things:
The size of the compressed data after decompression
As such, the following assumption is quite straightfoward: the sum of the two arguments to SrvNetAllocateBuffer is the sum of the two previous bullet points. Also, we can see that they both come from the variable “v9”, which IDA decompiled as a structure. It would make a lot of sense if v9 was actually the SMB2_COMPRESSION_TRANSFORM_HEADER_UNCHAINED structure, since it contains those information.
Thus, the call to SrvNetAllocateBuffer can be reversed to this.
We also know what v9 (which we renamed “compressHeader”) is (the SMB2_COMPRESSION_TRANSFORM_HEADER_UNCHAINED structure) which is handy as it is used throughout the function.
The next lines seem to be some kind of error handling, as they check for the return value of SrvNetAllocateBuffer, and, if there is no buffer, the function return early a value of what I assume to be an error code.
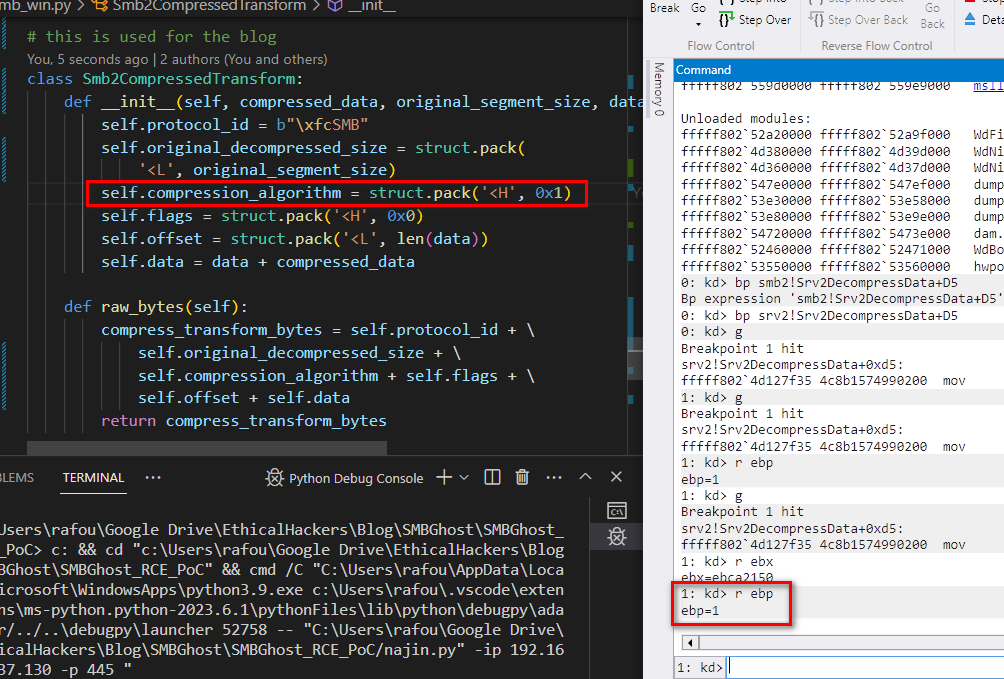
The next part is more interesting, as the name (SmbCompressionDecompress) would indicate it’s the place where the decompression occurs. let’s see what the arguments look like in WinDbg. We’ll use code borrowed from chompie to send our packets, and break right before the functions gets called. We can see from the assembly view in ida/ghidra that this call occurs at offset of 5D Srv2DecompressData, so let’s put a breakpoint at this address.
From the register holding v4 (the first argument given to SmbCompressionDecompress), we can see that v4 stores the value “1” just before SmbCompressionDecompress is called. From the packet we sent this could be the decompression algortihm used, which makes sense with what the function is supposed to do.
The value we sent as the compression algorithm seem to have been assigned to v4
The second argument to SmbCompressionDecompress is:
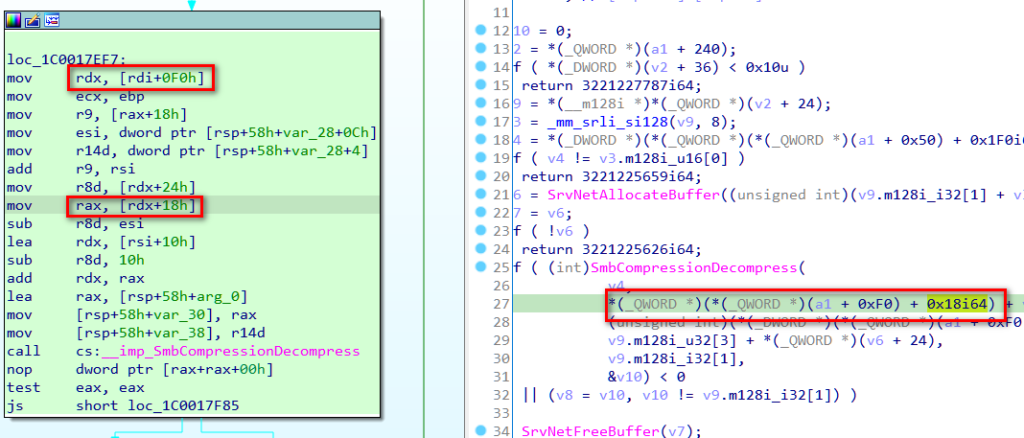
a1 seems to be a structure, as it is used to access offset of itself throughout the function. Moreover, a1 + 240 seems to be another structure, for the same reason. Let’s see what (a1 + 240) + 24i64) actually holds and what we can infer from it.
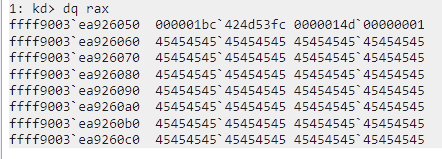
the result of " *(_QWORD *)(*(_QWORD *)(a1 + 240)" is store inside rax
rax points to this data
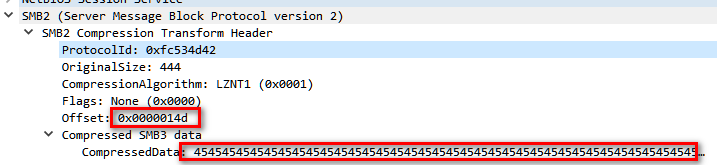
As we can see, (a1 + 0xF0) + 0x18i64) actually points to a structure that is pretty easy to identify, as it begins with the magic string”424d53fc”, which is the protocol ID of SMB. It also contain other very recognizable data, which we can find in the SMB compression packet we sent.
This leave very few doubt on what data we’re seeing, this is exactly the structure SMB2_COMPRESSION_TRANSFORM_HEADER_UNCHAINED which we talked about earlier.
Let’s remind the reader (and myself) that that compressHeader.Offset is “the offset, in bytes, from the end of this structure to the start of compressed data segment”. Knowing that the stucture size is actually 16 (0x10) bytes, it can be rewritten as such:
addressToEndOFCompressHeader + compressHeader.Offset
// which basically means
addressToCompressedData
So here we have it, the second argument given to SmbCompressionDecompress function is the adress to the compressed data. Let’s now analyze the third argument given, which is:
As we said earlier, a1 is probably a structure, and so is a1 + 0xF0. However this time we acess the offset 0x24. Let’s see what it hold inside windbg.
This was a bit of a hard one, until I realized 0x23b is 571 in decimal, and that is pretty close of the size of the compressed + uncompressed data we sent. If we add the smb header, it is exactly 571 bytes.
Thus, “(a1 + 0xF0) + 0x24i64)” could actually by rewritten to “msgSize”. So what is msgSize – offset – 0x10 ?
Well, if we do the whole smb packet size minus the offset (which is the size of the uncompressed data), minus 0x10 (which is the size of the smb stucture), we’re left with the size of the compressed data. Therefore, the third argument of SmbCompressionDecompress is the size of the compressed data sent.
The 4th argument is:
v9.m128i_u32[3] + *(_QWORD *)(v6 + 0x18),
From windbg, we can see that this argument is actually an address. The data pointed by this address does not seem to hold any meaningful data, at least before the call, but we’ll make a guess here. From the arguments passed to SmbCompressionDecompress, this is the only address left. Since this function is used for decompression we need a buffer address to hold the data once decompressed. This buffer adress can be either passed as an argument, or returned. However:
v6 was returned by SrvNetAllocateBuffer, which would indicate that this argument is indeed some sort of buffer
The returned value of SmbCompressionDecompress seems to be used for error checking, and not as a buffer address
With those informations, the 4th argument seems to be the pointer where the decompressed data is going to be.
We already reversed the 5th argument when dealing with the call to SrvNetAllocateBuffer, we already now it is equal to to size of the compressed data before compression, which comes from the smb compression packet.
Now about the 6th and last argument, we can see that it is compared right after the call to a value we already reversed: the size of the data before compression. It is possible that it is a check done in order to verify that after decompression, the data is equal to what the client said the size of the data should be.
We can also see from windbg that the value is indeed equal to the data we sent inside our SMB compressed packet.
The last args contains the size of the compressed data before compression
Just from reversing the arguments given to those two functions (SrvNetAllocateBuffer and SmbCompressionDecompress), we have basically every variable/structured used throughout the Srv2DecompressData function. Here’s what the function look like once we put all those information inside IDA. Some structure, such as “workitem”, comes from the litterature on SMBGhost, but were not that useful for reversing that particular function.
__int64 __fastcall Srv2DecompressData(workItem *workItem)
{
struct_psbhRequest *packet; // rax
__m128i compressHeaderSecondPart; // xmm0
unsigned int algo; // ebp
SRVNET_BUFFER_HDR *pBufferHeader; // rax MAPDST
SmbCompressHeader compressHeader; // [rsp+30h] [rbp-28h]
int sizeReturnedBySmbCompressionDecompress; // [rsp+60h] [rbp+8h] MAPDST BYREF
sizeReturnedBySmbCompressionDecompress = 0;
packet = workItem->psbhRequest;
if ( packet->dwMsgSize < 0x10u )
return 3221227787i64;
compressHeader = *packet->compressheader;
compressHeaderSecondPart = _mm_srli_si128(compressHeader, 8);
algo = *(*(workItem->qword50 + 496i64) + 140i64);
if ( algo != compressHeaderSecondPart.CompressionAlgo[0] )
return 3221225659i64;
pBufferHeader = SrvNetAllocateBuffer( // pBufferHeader => RBX
(compressHeader.OriginalCompressedSegmentSize + compressHeaderSecondPart.offset[1]),
0i64);
if ( !pBufferHeader )
return 3221225626i64;
if ( SmbCompressionDecompress(
algo,
workItem->psbhRequest->compressheader + compressHeader.Offset + 0x10i64,// Pointer to the start of the compressed data. 16 => size of compressHeader.
// compressheader.offset -> dw poi(poi(rdi+f0)+18)+c L1
(workItem->psbhRequest->dwMsgSize - compressHeader.Offset - 0x10),// Size of compressed data
&pBufferHeader->pNetRawBuffer[compressHeader.Offset],// Pointer where decompressed data is going to be
compressHeader.OriginalCompressedSegmentSize,// compressheader -> dq poi(poi(rdi+f0)+18)
&sizeReturnedBySmbCompressionDecompress) < 0
|| sizeReturnedBySmbCompressionDecompress != compressHeader.OriginalCompressedSegmentSize )
{
SrvNetFreeBuffer(pBufferHeader);
return 3221227787i64;
}
if ( compressHeader.Offset )
memmove( // workItem->psbhRequest -> rax
// worItem -> rdi
pBufferHeader->pNetRawBuffer, // Pointer to start of data that was not compressed to begin with in new header
//
(workItem->psbhRequest->compressheader + 0x10i64),// pointer to start of data that was not compressed to begin with
compressHeader.Offset); // Size of data not compressed to begin with
//
pBufferHeader->dwMsgSize = compressHeader.Offset + sizeReturnedBySmbCompressionDecompress;// MDL -> dq poi(rbx+38)
Srv2ReplaceReceiveBuffer(workItem, pBufferHeader);
return 0i64;
}
What did we learn
Although we didn’t delve into the specifics of the SMBGhost vulnerability, we took an essential step in comprehending an exploit by examining the intended function of the affected component.
Additionally, I wanted to dedicate some time to discussing the reverse process, as existing literature on SMBGhost doesn’t provide much detail on this aspect.
While we’ve gained a deeper understanding of Srv2DecompressData’s internals, in the upcoming article, we will explore the reverse-engineered function to further enhance our knowledge of its typical use cases. From there, we’ll begin to explain how SMBGhost can be exploited based on these use cases.
References
I could not have written any of this without the amazing researchers that published their findings on this vulnerability. So a big thanks to them. Here are the main articles I based this article on: